Benchmarking Rust for Serverless
Let’s start with two very important questions:
- Why should I care to benchmark Rust since it’s already super fast?
That’s the question we’ll try to answer in this post!
- Will there be a 🍕 demo?
Of course, you know that I’m a true 🍕🍕🍕 lover!
What’s so special about Serverless?
Benchmarking is not specific to serverless. But in serverless components, such as AWS Lambda functions, performance really matters for two main reasons:
Cold start duration (good news, Rust is really performant as you can see in my daily updated benchmark)
Runtime duration, as AWS is billing per millisecond.
Let’s see how we can measure and improve this runtime duration using benchmarks!
What are we going to benchmark?
Let’s take a very simple example:a function which returns the pizza of the day. 🍕 (I told you)
We will compare two different implementations:
- one with HashMap -
std::collections::HashMap - one with Vec -
std::vec::Vec
(if you don’t know much about Rust, you might wish to take a look at some basic Rust code before we start, like the Rust book or my Rust Youtube channel 😇)
First, let’s define our PizzaStore trait:
pub trait PizzaStore {
fn get_pizza_of_the_day(&self, day_index: i32) -> &str;
}
And our first implementation with HashMap:
// let's make sure we don't initialize a new HashMap each time
pub struct PizzaHashMap<'a> {
cache: HashMap<i32, &'a str>,
}
impl<'a> PizzaHashMap<'a> {
pub fn new() -> Self {
PizzaHashMap {
cache: HashMap::from([
(0, "margherita"),
(1, "deluxe"),
(2, "veggie"),
(3, "mushrooms"),
(4, "bacon"),
(5, "four cheese"),
(6, "pepperoni"),
// what's your favorite?
]),
}
}
}
impl<'a> PizzaStore for PizzaHashMap<'a> {
// let's get the pizza of the day from the cache (HashMap)
fn get_pizza_of_the_day(&self, day_index: i32) -> &str {
match self.cache.get(&day_index) {
Some(&pizza) => pizza,
None => panic!("could not find the pizza"),
}
}
}
Writing our first benchmark
There are quite some crates to create benchmarks but we’ll use criterion here.
Let’s start by creating a benches folder containing a benchmark.rs file and add our first criterion:
fn criterion_hashmap(c: &mut Criterion) {
let mut rng = rand::thread_rng();
// we create the cache outside of the bench function so only one HashMap will be created
let pizza_store_hashmap = PizzaHashMap::new();
// we call get_pizza_of_the_day with a random day index
c.bench_function("with hashmap", |b| b.iter(|| pizza_store_hashmap.get_pizza_of_the_day(rng.gen_range(0..7))));
}
We also need a bench group (as we will add more criterion later)
criterion_group!(benches, criterion_hashmap);
criterion_main!(benches);
That’s it! Let’s run it with cargo bench
By default, it runs our function for about 5seconds (that’s about 300M+ iterations)
Running benches/benchmark.rs (target/release/deps/benchmark-2f28819806c8c7c9)
with hashmap time: [13.069 ns 13.090 ns 13.114 ns]
Left and right values are lower and upper bounds.
The number in the middle is the best estimation on how long each iteration is likely to take.
Note that those 3 numbers are extremely alike. This won’t be the case if you’re depending on networking for instance.
Second implementation: with Vec
Let’s create a different implementation using Vec instead of using HashMap using the following code.
pub struct PizzaVec<'a> {
cache: Vec<&'a str>
}
impl<'a> PizzaVec<'a> {
pub fn new() -> Self {
PizzaVec {
cache: vec!["margherita","deluxe","veggie","mushrooms","bacon","four cheese","pepperoni"],
}
}
}
impl<'a> PizzaStore for PizzaVec<'a> {
fn get_pizza_of_the_day(&self, day_index: i32) -> &str {
match self.cache.get(day_index as usize) {
Some(&pizza) => pizza,
None => panic!("could not find the pizza"),
}
}
}
Let’s create a new criterion so we can compare (that’s the goal of benchmarks!)
Back in benchmark.rs we can add
fn criterion_vec(c: &mut Criterion) {
let mut rng = rand::thread_rng();
let pizza_store_vec = PizzaVec::new();
c.bench_function("with vector", |b| b.iter(|| pizza_store_vec.get_pizza_of_the_day(rng.gen_range(0..7))));
}
and update our group to include this new criterion:
criterion_group!(benches, criterion_hashmap, criterion_vec);
so we can re-run our benchmarks with : cargo bench
and check the result!
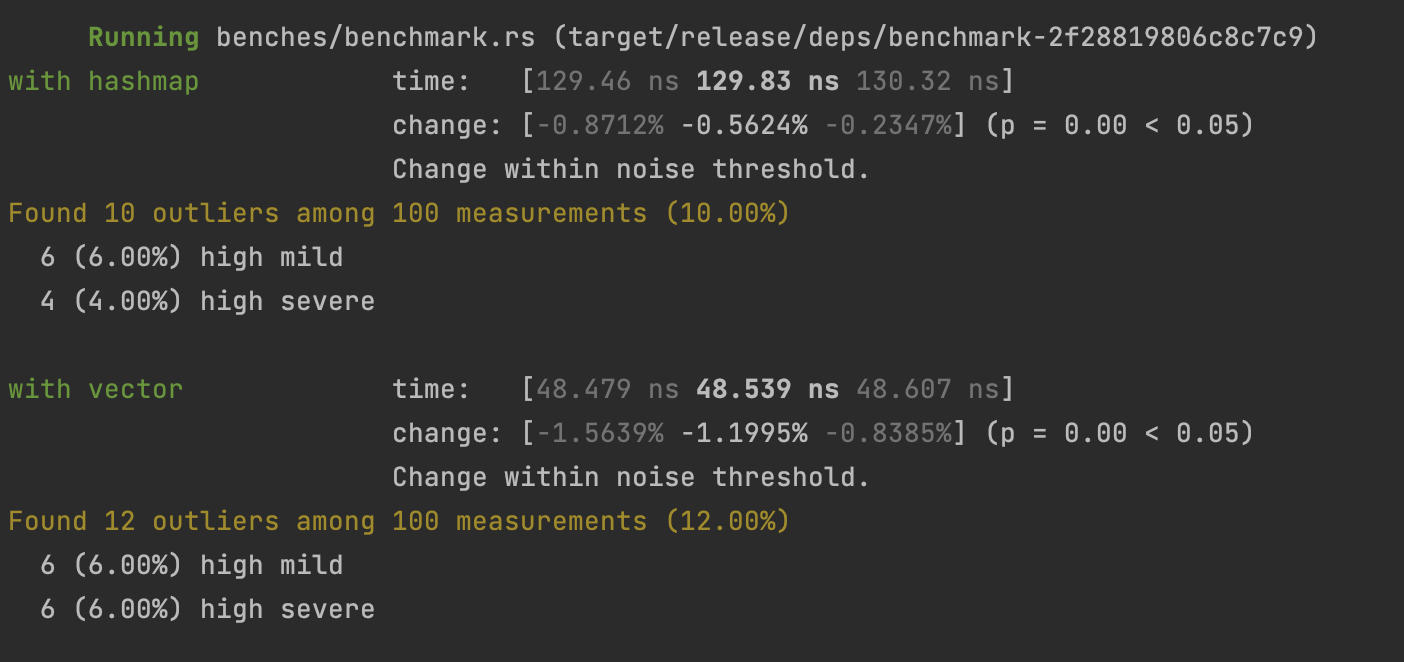
with hashmap time: [13.096 ns 13.117 ns 13.141 ns]
with vector time: [7.5832 ns 7.5958 ns 7.6097 ns]
By replacing our HashMap with a Vec, our program is now running almost twice as fast!
This is a great reminder on how the data structure choice is really important depending on the use case 😇
Ok great, but how does it translate to Serverless?
Two AWS Lambda Functions have been deployed embedding each one of the implementations.
Each lambda function calls 10_000_000 times get_pizza_of_the_day
In us-east-1 with 128MB, here are the results:
| Implementation | Runtime duration |
|---|---|
| HashMap | 267.92 ms |
| Vec | 87.98 ms 🤯🤯 |
That’s it!
Of course this was a simple example but I hope I’ve convinced you to use benchmarks to optimize your code!
Bonus question: where does this overhead come from?
Stay tuned for the next blog post about Rust profiling!
❤️ ❤️ ❤️ Did you like this content? ❤️ ❤️ ❤️
- Follow me on LinkedIn & X
- Check my Rust Youtube channel
- Share with your friends <3